本文共 16712 字,大约阅读时间需要 55 分钟。
作者:龚麒,广发证券信息技术部高级前端工程师,负责广发证券金钥匙项目的React Native改造,及广发证券有问必答业务的微信小程序版的开发,在混合开发和各类跨端解决方案应用上具有丰富经验。
责编:陈秋歌() 2017 年 7 月 8 日(星期六),「」将在 CSDN 学院召开,龚麒已受邀参加,并围绕前端状态管理,深度分享广发证券在该领域做出的一系列探索与实践。届时,您将了解当前最为火热的两款前端状态管理工具,学会评析不同状态管理方案的,并在选型时做出合理取舍。
前言
前端的发展日新月异,Angular、React、Vue 等前端框架的兴起,为我们的应用开发带来新的体验。React Native、Weex、微信小程序等技术方案的出现,又进一步扩展了前端技术的应用范围。随着这些技术的革新,我们可以更加便利地编写更高复杂度、更大规模的应用,而在这一过程中,如何优雅的管理应用中的数据状态成为了一个需要解决的问题。
为解决这一问题,我们在项目中相继尝试了当前热门的前端状态管理工具,对前端应用状态管理方案进行了深入探索与思考。
Dive into Redux
Redux 是什么
Redux 是前端应用的状态容器,提供可预测的状态管理,其基本定义可以用下列公式表示:
(state, action) => newState
其特点可以用以下三个原则来描述。
单一数据源
在 Redux 中,整个应用的状态以状态树的形式,被存储在一个单例的 store 中。
状态数据只读
惟一改变状态数据的方法是触发 action,action 是一个用于描述已发生事件的普通对象。
使用纯函数修改状态
在 Redux 中,通过纯函数,即 reducer 来定义如何修改 state。
从上述原则中,可以看出,构成 Redux 的主要元素有 action、reducer、store,借用一张经典图示(见图1),可以进一步理解 Redux 主要元素和数据流向。
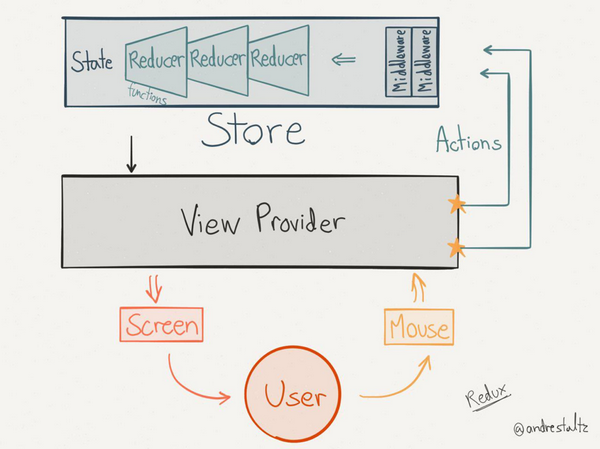
图1 展示了Redux的主要元素和数据流向
探索 The Redux way
异步方案选型
Redux 中通过触发 action 修改状态,而 action 是一个普通对象,action creator 是一个纯函数。如何在 action creator 中融入、管理我们的异步请求,是在实际开发中首先需要解决的问题。
当前 Redux 生态活跃,出现了不少异步管理中间件。在我们的实践中,认为大致可以分为两类。
(1)以 redux-thunk 为代表的中间件
使用 redux-thunk 完成一个异步请求的过程如下:
//action creatorfunction loadData(userId){ return (dispatch,getState) => { dispatch({ type:'LOAD_START'}) asyncRequest(userId).then(resp=>{ dispatch({ type:'LOAD_SUCCESS',resp}) }).catch(error=>{ dispatch({ type:'LOAD_FAIL',error}) }) }}//componentcomponentDidMount(){ this.props.dispatch(loadData(this.props.userId));} 在上述示例中,引入 redux-thunk 后,我们将异步处理和业务逻辑定义在一个方法中,利用中间件机制,将方法的执行交由中间件管理。
上例是一个简单的异步请求,在代码中我们需要主动地根据异步请求的执行状态,分别触发请求开始、成功和失败三个 action。这一过程显得繁琐,当应用中有大量这类简单请求时,项目中会充满这种重复代码。
针对这一问题,出现了一些用于简化这类简单请求的工具。实际开发中,我们选择了 redux-promise-middleware 中间件,使用这一中间件来完成上述请求的代码示例如下:
//action creatorfunction loadData(userId){ return { type:types.LOAD_DATA, payload:asyncRequest(userId) }}//componentcomponentDidMount(){ this.props.dispatch(loadData(this.props.userId));} 引入 redux-promise-middleware 中间件,我们在 action creator 中返回一个与 redux action 结构一致的普通对象,不同的是,payload 属性是一个返回 Promise 对象的异步方法。通过将异步方法的执行过程交由 redux-promise-middleware 中间件处理,中间件会帮助我们处理异步请求的状态,根据异步请求的结果为当前操作类型添加 PEDNGING/FULFILLED/REJECTED 状态,我们的代码得到大幅简化。
redux-promise-middleware 中间件适用于简化简单请求的代码,开发中推荐混合使用 redux-promise-middleware 中间件和 redux-thunk。
(2)以 redux-saga 为代表的中间件
以 redux-thunk 为代表的中间件可以满足一般的业务场景,但当业务对用户事件、异步请求有更细粒度的控制需求时,redux-thunk 不能便利的满足。此时,可以选择以 redux-saga 为代表的中间件。
redux-saga 可以理解为一个和系统交互的常驻进程,其中,Saga 可简单定义如下:
Saga = Worker + Watcher
采用 redux-saga 完成异步请求,示例如下:
//sagafunction* loadUserOnClick(){ yield* takeLatest('LOAD_DATA',fetchUser); } function* fetchUser(action){ try{ yield put({type:'LOAD_START'}); const user = yield call(asyncRequest,action.payload); yield put({type:'LOAD_SUCCESS',user}); }catch(err){ yield put({type:'LOAD_FAIL',error}) }}//component dispatch({type:'LOAD_DATA',payload:'001'})}>load data 与 redux-thunk 相比,使用 redux-saga 有几处明显的变化:
- 在组件中,不再
dispatch(action creator),而是dispatch(pure action); - 组件中不再关注由谁来处理当前 action,action 经由 root saga 分发;
- 具体业务处理方法中,通过提供的 call/put 等帮助方法,声明式的进行方法调用;
- 使用 ES6 Generator 语法,简化异步代码语法。
除去上述这些不同点,redux-saga 真正的威力,在于其提供了一系列帮助方法,使得对于各类事件可以进行更细粒度的控制,从而完成更加复杂的操作。
简单列举如下:
- 提供 takeLatest/takeEvery/throttle 方法,可以便利的实现对事件的仅关注最近事件、关注每一次、事件限频;
- 提供 cancel/delay 方法,可以便利的取消、延迟异步请求;
- 提供 race(effects),[…effects] 方法来支持竞态和并行场景;
- 提供 channel 机制支持外部事件。
在 Redux 生态中,除了 redux-saga 中间件,还有另一个中间件,redux-observable 也可以满足这一场景。
redux-observable 是基于 RxJS 的用于处理异步请求的中间件,借助 RxJS 的各种操作符和帮助方法,redux-observable 也能实现对各类事件的细粒度操作,比如取消、限频、延迟请求等。
redux-saga 与 redux-observable 适用于对事件操作有细粒度需求的场景,同时他们也提供了更好的可测试性,当你的应用逐渐复杂需要更加强大的工具时,他们会成为很好的帮手。
应用状态设计
如何设计应用状态的数据结构是一个值得思考的问题,在实践中,我们总结了两点数据划分的指导性原则,应用状态扁平化和抽离公共状态。
(1) 应用状态扁平化
在我们的项目中,有联系人、聊天消息和当前联系人对象。最初我们采用如下数据结构:
{contacts:[ { id:'001', name:'zhangsan', messages:[ { id:1, content:{ text:'hello' }, status:'succ' }, ... ] }, ...],selectedContact:{ id:'001', name:'zhangsan', messages:[ { id:1, content:{ text:'hello' }, status:'succ' }, ... ] }} 采用上述数据机构,带来几个问题。
- 消息对象与联系人对象耦合,消息对象的变更操作引发联系人对象的变更操作;
- 联系人集合和当前联系人对象数据冗余,当数据更新时需要多处修改来保持数据一致性;
- 数据结构嵌套过深,不便于数据更新,一定程度上导致更新时的耗时增加。
将数据扁平化、解除耦合,得到如下数据结构:
{contacts:[ { id:'001', name:'zhangsan' }, ...],messages:{ '001':[ { id:1, content:{ text:'hello' }, status:'succ' }, ... ], ...},selectedContactId:'001'} 相对于之前的问题,上述数据结构具有以下优点:
- 细粒度的更新数据,进而细粒度控制视图的渲染;
- 结构清晰,避免更新数据时,复杂的数据操作;
- 去除冗余数据,避免数据不一致。
(2)抽离公共状态
在领域对象之外,往往还有另外一些与请求过程相关的状态数据,如下所示:
{ user: { isError: false, // 加载用户信息失败 isLoading: false, // 加载用户中 ... entity: { ... }, }, messages: { isLoading: true, // 加载消息中 nextHref: '/api/messages?offset=200&size=100', // 消息分页数据 ... entities: { ... }, }, authors: { isError: false, // 加载作者失败 isLoading: false, // 加载作者中 nextHref: '/api/authors?offset=50&size=25', // 作者分页数据 ... entities: { ... }, },} 上述数据结构中,我们按照功能模块将状态数据内聚。采用上述结构,会导致我们需要写很多基本重复的 action,如下所示:
{ type: 'USER_IS_LOADING', payload: { isLoading, },}{ type: 'MESSAGES_IS_LOADING', payload: { isLoading, },}{ type: 'AUTHORS_IS_LOADING', payload: { isLoading, },}... 我们分别为 user 、message 、author 定义了一系列 action,它们作用类似,代码重复。为解决这一问题,我们可以将这类状态数据抽离,不再简单的按照功能模块内聚,抽离后的状态数据如下所示:
{ isLoading: { user: false, messages: true, authors: false, ... }, isError: { userEdit: false, authorsFetch: false, ... }, nextHref: { messages: '/api/messages?offset=200&size=100', authors: '/api/authors?offset=50&size=25', ... }, user: { ... entity: { ... }, }, messages: { ... entities: { ... }, }, authors: { ... entities: { ... }, },} 采用这一结构,可以避免定义大量相似的 action type,避免编写重复的 action。
修改状态数据
将应用状态数据不可变化是使用 Redux 的一般范式,有多种方式可以实现不可变数据的效果,我们分别尝试了 immutable.js 和 seamless-immutable.js,并在实际开发中选择了 seamless-immutable.js。
(1)immutable.js
immutable.js 是一个知名度很高的不可变数据实现库。它为人称道的是基于共享数据结构所带来的数据修改时的高性能,但是在我们的使用过程中,发现其易用性不够友好,使用体验并不美好。
- 首先,immutable.js 实现的是 shallowly immutable,如下示例中,notFullyImmutable 中的对象属性仍然是可变的。
var obj = {foo: "original"};var notFullyImmutable = Immutable.List.of(obj);notFullyImmutable.get(0) // { foo: 'original' }obj.foo = "mutated!";notFullyImmutable.get(0) // { foo: 'mutated!' } 另外,immutable.js 使用了自定义的数据结构,这意味着贯穿我们的应用都需要明确当前使用的是 immutable.js 的数据结构。获取数据时,需要使用 get 方法,而不能使用
obj.prop或者obj[prop]。在需要将数据同外部交互,如存储或者请求时,需要将特有数据结构转换成原生 JavasScript 对象。最后,以
state.set('key',obj)形式更新状态时,obj 对象不能自动的 immutable 化。
(2)seamless-immutable.js
上述问题使得我们在开发中不断地需要停下来思考当前写法是否正确,于是我们继续尝试,最后选择使用 seamless-immutable.js 来帮助实现不可变数据。
seamless-immutable.js 意为无缝的 immutable,与 immutable.js 不同,它没有定义新的数据结构,其基本使用如下所示:
var array = Immutable(["totally", "immutable", {hammer: "Can’t Touch This"}]);array[1] = "I'm going to mutate you!"array[1] // "immutable"array[2].hammer = "hm, surely I can mutate this nested object..."array[2].hammer // "Can’t Touch This"for (var index in array) { console.log(array[index]); }// "totally"// "immutable"// { hammer: 'Can’t Touch This' } 根据我们的使用体验,seamless-immutable.js 易用性优于 immutable.js。但是在选择之前,有一点需要了解的是,在数据修改时,seamless-immutable.js 性能低于 immutable.js。数据嵌套层级越深,数据量越大,性能差异越明显。这里需要根据业务特点来做选择,我们的业务没有大批量的深度数据修改需求,易用性比性能更重要。
在应用中使用
Redux 可以应用在多种场景,在我们的开发中,已经将它应用到了 React Native、Angular 1.x 重构和微信小程序的项目上。
在前文介绍 Redux 三原则时提到,Redux 具有单一数据源,触发 action 时,Redux store 在执行状态更新逻辑后,会执行注册在 store 上的事件处理函数。
基于上述过程,在简单的 HTML 中可以如下使用 Redux:
const initialState = { count:0};const counterReducer = (state=initialState,action) => {...}const {createStore} = Redux;const store = createStore(counterReducer);const renderApp = () =>{ const {count} = store.getState(); document.body.innerHTML = ` Clicked : ${count} times
`;};store.subscribe(renderApp);renderApp(); 结合前端框架使用 Redux 时,社区中已经有了 react-redux、ng-redux 这类的帮助工具,甚至对应微信小程序,也有了类似的实现方案。其实现原理均一致,都是通过全局对象绑定 Redux store,使得在应用组件中可以获得 store 中的状态数据,并向 store 注册事件处理函数,用来在状态变更时触发视图的更新。
当我们在项目中应用 Redux 时,也对代码文件的组织进行了一番探索。通常我们按照如下方式组织代码文件:
|--components/|--constants/ ----userTypes.js|--reducers/ ----userReducer.js|--actions/ ----userAction.js
严格遵循这一模式并无不可,但是当项目规模逐渐扩大,文件数量增多后,切换多文件夹寻找文件变得有些繁琐,在这一时刻,可以考虑尝试 Redux Ducks 模式。
|--components |--redux ----userRedux
所谓 Ducks 模式,也即经典的鸭子类型。这里将同一领域内,Redux 相关元素的文件合并至同一个文件 userRedux 中,可以避免为实现一个简单功能频繁在不同目录切换文件。
与此同时,根据我们的使用经验,鸭子模式与传统模式应当灵活的混合使用。当业务逻辑复杂,action与reducer各自代码量较多时,按照传统模式拆分可能是更好的选择。此时可以如下混合使用两种模式:
|--modules/ ----users/ ------userComponent.js ------userConstant.js ------userAction.js ------userReducer.js ----messages/ ------messageComponent.js ------messageRedux.js
Dive into Mobx
Mobx 是什么
Mobx 是一个简单、可扩展的前端应用状态管理工具。Mobx 背后的哲学很简单:当应用状态更新时,所有依赖于这些应用状态的观察者(包括UI、服务端数据同步函数等),都应该自动得到细粒度地更新。
Mobx 中主要包含如下元素:
State
State 是被观察的应用状态,状态是驱动你的应用的数据。
Derivations
Derivations 可以理解为衍生,它是应用状态的观察者。Mobx 中有两种形式的衍生,分别是 Computed values 和 Reactions。其中,Computed values 是计算属性,它的数据通过纯函数由应用状态计算得来,当依赖的应用状态变更时,Mobx 自动触发计算属性的更新。Reactions 可简单理解为响应,与计算属性类似,它响应所依赖的应用状态的变更,不同的是,它不产生新的数据,而是输出相应的副作用(side effects),比如更新UI。
Actions
Actions 可以理解为动作,由应用中的各类事件触发。Actions 是变更应用状态的地方,可以帮助你更加清晰的组织你的代码。
Mobx 项目主页中的示例图(见图2),清晰的描述了上述元素的关系:

Mobox项目主页的示例图
探索 The Mobx Way
在探索 Redux 的过程中,我们关注异步方案选型、应用状态设计、如何修改状态以及怎样在应用中使用。当我们走进 Mobx,探索 Mobx 的应用之道时,分别从应用状态设计、变更应用状态、响应状态变更以及如何在实际、复杂项目中应用进行了思考。
应用状态设计
设计应用状态是开始使用 Mobx 的第一步,让我们开始设计应用状态:
class Contact { id = uuid(); @observable firstName = "han"; @observable lastName = "meimei"; @observable messages = []; @observable profile = observable.map({}) @computed get fullName() { return `${ this.firstName}, ${ this.lastName}`; }} 上述示例中,我们定义领域模型 Contact 类,同时使用 ES.next decorator 语法,用 @observable 修饰符定义被观察的属性。
领域模型组成了应用的状态,定义领域模型的可观察属性是 Mobx 中应用状态设计的关键步骤。在这一过程中,我们需要关注两方面内容,分别是 Mobx 数据类型和描述属性可观察性的操作符。
(1)Mobx 数据类型
Mobx 内置了几种数据类型,包括 objects、arrays、maps 和 box values。
- objects 是 Mobx 中最常见的对象,示例中 Contact 类的实例对象,或者通过
mobx.observable({ key:value})定义的对象均为 Observable Objects。 - box values 相对来说使用较少,它可以将 JavaScript 中的基本类型如字符串转为可观察对象。
- arrays 和maps 是 Mobx 对 JavaScript 原生 Array 和 Map 的封装,用于实现对更复杂数据结构的监听。
当使用 Mobx arrays 结构时,有一个需要注意的地方,如下所示,经封装后,它不再是一个原生 Array 类型了。
Array.isArray(observable([1,2,3])) === false
这是一个我们最初使用时,容易走进的陷阱。当需要将一个 observable array 与第三方库交互使用时,可以对它创建一份浅复制,像下面这样,转为原生 JavaScript:
Array.isArray(observable([]).slice()) === true
默认情况下,领域模型中被预定义为可观察的属性才能被监听,而为实例对象新增的属性,不能被自动观察。使用 Mobx maps,即使新增的属性也是可观察的,我们不仅可以响应集合中某一元素的变更,也能响应新增、删除元素这些操作。
除了使用上述几种数据类型来定义可观察的属性,还有一个很常用的概念,计算属性。通常,计算属性不是领域模型中的真实属性,而是依赖其他属性计算得来。系统收集它对其他属性的依赖关系,仅当依赖属性变更时,计算属性的重新计算才会被触发。
(2)描述属性可观察性的操作符
Mobx 中的 Modifiers 可理解为描述属性可观察性的操作符,被用来在定义可观察属性时,改变某些属性的自动转换规则。
在定义领域模型的可观察属性时,有如下三类操作符值得关注:
observable.deep
deep 操作符是默认操作符,它会递归的将所有属性都转换为可观察属性。通常情况下,这是一个非常便利的方式,无需更多操作即可将定义的属性进行深度的转换。
observable.ref
ref 操作符表示观察的是对象的引用关系,而不关注对象自身的变更。
例如,我们为 Contact 类增加 address 属性,值为另一个领域模型 Address 的实例对象。通过使用 ref 修饰符,在 address 实例对象的属性变更时,contact 对象不会被触发更新,而当 address 属性被修改为新的 address 实例对象,因为引用关系变更,contact 对象被触发更新。
let address = new Address();class Contact { ... @observable.ref address = address;}let contact = new Contact();address.city = 'New York'; //不会触发更新通知contact.address = new Address();//引用关系变更,触发更新通知observable.shallow
shallow 操作符表示对该属性进行一个浅观察,通常用于描述数组类型属性。shallow 是与 deep 相对的概念,它不会递归的将子属性转换为可观察对象。
let plainObj = {key:'test'};class Contact { ... @observable.shallow arr = [];}let contact = new Contact();contact.arr.push(plainObj); //plainObj还是一个plainObj//如果去掉shallow修饰符,plainObj被递归转换为observable object
当我们对 Mobx 的使用逐渐深入,应当再次检查项目中应用状态的设计,合理地使用这些操作符来限制可观察性,对于提升应用性能有积极意义。
修改应用状态
在 Mobx 中修改应用状态是一件很简单的事情,在前文的示例中,我们直接修改领域模型实例对象的属性值来变更应用状态。
class Contact { @observable firstName = 'han;}let contact = new Contact();contact.firstName = 'li'; 像这样修改应用状态很便捷,但是会来带两个问题:
- 需要修改多个属性时,每次修改均会触发相关依赖的更新;
- 对应用状态的修改分散在项目多个地方,不便于跟踪状态变化,降低可维护性。
为解决上述问题,Mobx 引入了 action。在我们的使用中,建议通过设置 useStrict(true),使用 action 作为修改应用状态的唯一入口。
class Contact { @observable firstName = 'han'; @observable lastName = "meimei"; @action changeName(first, last) { this.firstName = first; this.lastName = last; }}let contact = new Contact();contact.changeName('li', 'lei'); 采用 @action 修饰符,状态修改方法被包裹在一个事务中,对多个属性的变更变成了一个原子操作,仅在方法结束时,Mobx 才会触发一次对相关依赖的更新通知。与此同时,所有对状态的修改都统一到应用状态的指定标识的方法中,一方面提升了代码可维护性,另一方面,也便于调试工具提供有效的调试信息。
需要注意的是 action 只能影响当前函数作用域,函数中如果有异步调用并且在异步请求返回时需要修改应用状态,则需要对异步调用也使用 aciton 包裹。当使用 async/await 语法处理异步请求时,可以使用 runInAction 来包裹你的异步状态修改过程。
class Contact { @observable title ; @action getTitle() { this.pendingRequestCount++; fetch(url).then(action(resp => { this.title = resp.title; this.pendingRequestCount--; })) } @action getTitleAsync = async () => { this.pendingRequestCount++; const data = await fetchDataFromUrl(url); runInAction("update state after fetching data", () => { this.title = data.title; this.pendingRequestCount--; }) }} 上述是示例中包含了在 Mobx action 中处理异步请求的过程,这一过程与我们在普通 JavaScript 方法中处理异步请求基本一致,唯一的差别,是对应用状态的更新需要用 action 包裹。
响应状态变更
在 Mobx action 中更新应用状态时,Mobx 自动的将变更通知到相关依赖的部分,我们仅需关注如何响应变更。Mobx 中有多种响应变更的方法,包括 autorun、reaction、when 等,本节探讨其使用场景。
(1)autorun
autorun 是Mobx中最常用的观察者,当你需要根据依赖自动的运行一个方法,而不是产生一个新值,可以使用 autorun 来实现这一效果。
class Contact { @observable firstName = 'Han'; @observable lastName = "meimei"; constructor() { autorun(()=>{ console.log(`Name changed: ${ this.firstName}, ${ this.lastName}`); }); this.firstName = 'Li'; }}// Name changed: Han, meimei// Name changed: Li, meimei (2)reaction
从上例输出的日志可以看出,autorun 在定义时会立即执行,之后在依赖的属性变更时,会重新执行。如果我们希望仅在依赖状态变更时,才执行方法,可以使用 reaction。
reaction 可以如下定义:
reaction = tracking function + effect function
其使用方式如下所示:
reaction(() => data, data => { sideEffect }, options?) 函数定义中,第一个参数即为 tracking function,它返回需要被观察的数据。这个数据被传入第二个参数即 effect function,在 effect function 中处理逻辑,产生副作用。
在定义 reaction 方法时,effect function 不会立即执行。仅当 tracking function 返回的数据变更时,才会触发 effect function 的执行。通过将 autorun 拆分为 tracking function 和 effect function,我们可以对监听响应进行更细粒度的控制。
(3) when
autorun 和reaction 可以视为长期运行的观察者,如果不调用销毁方法,他们会在应用的整个生命周期内有效。如果我们仅需在特定条件下执行一次目标方法,可以使用 when。
when 的使用方法如下所示:
when(debugName?, predicate: () => boolean, effect: () => void, scope?)
与 reaction 类似,when 主要参数有两个,第一个是 tracking function,返回一个布尔值,仅当布尔值为 true 时,第二个参数即 effect function 会被触发执行。在执行完成后,Mobx 会自动销毁这一观察者,无需手动处理。
在应用中使用
Mobx 是一个独立的应用状态管理工具,可以应用在多种架构的项目中。当我们在 React 项目中使用 Mobx 时,使用 mobx-react 工具库可以帮助我们更便利的使用。
Mobx 中应用状态分散在各个领域模型中,一个领域模型可视为一个 store。在我们的实际使用中,当应用规模逐渐复杂,会遇到这样的问题:
当我们需要在一个 store 中使用或更新其他 store 状态数据时,应当如何处理呢?
Mobx 并不提供这方面的意见,它允许你自由的组织你的代码结构。但是在面临这一场景时,如果仅是互相引用 store,最终会将应用状态互相耦合,多个 store 被混合成一个整体,代码的可维护性降低。
为我们带来这一困扰的原因,是因为 action 处于某一 store 中,而其本身除了处理应用状态修改之外,还承载了业务逻辑如异步请求的处理过程。实际上,这违背了单一职责的设计原则,为解决这一问题,我们将业务逻辑抽离,混合使用了 Redux action creator 的结构。
import contactStore from '../../stores/contactStore';import messageStore from '../../stores/messageStore';export function syncContactAndMessageFromServer(url) { const requestType = requestTypes.SYNC_DATA; if (requestStore.getRequestByType(requestType)) { return; } requestStore.setRequestInProcess(requestType, true); return fetch(url) .then(response => response.json()) .then(data => { contactStore.setContacts(data.contacts); messageStore.setMessages(data.messages); requestStore.setRequestInProcess(requestType, false); });} 上述示例中,我们将业务逻辑抽离,在这一层自由的引用所需的 Mobx store,并在业务逻辑处理结束,调用各自的 action 方法去修改应用状态。
这种解决方案结合了 Redux action creator 思路,引入了单独的业务逻辑层。如果不喜欢这一方式,也可以采用另一种思路来重构我们的 store。
在这种方法里,我们将 store 与 action 拆分,在 store 中仅保留属性定义,在 action 中处理业务逻辑和状态更新,其结构如下所示:
export class ContactStore { @observable contacts = []; // ...other properties}export class MessageStore { @observable messages = observable.map({}); // ...other properties}export MainActions { constructor(contactStore,messageStore) { this.contactStore = contactStore, this.messageStore = messageStore } @action syncContactAndMessageFromServer(url) { ... }} 两种方法的均能解决问题,可以看出第二种方法对 store 原结构改动较大,在我们的实际开发中,使用第一种方法。
未完待续……
如何选择你的状态管理方案?Redux、Mobx 关键差异有哪些?选择方案时应做出哪些考虑?提前阅读完整版?欢迎扫码,关注“CSDN前端开发者说”公众号,畅快阅读全文!

本文选自《程序员》7期“前端开发创新实践”特别专题。本期杂志即将上市,欢迎。
2017年7月8日(星期六),「“前端开发创新实践”线上峰会」将在 CSDN 学院召开。本次峰会集结来自Smashing Magazine、美国Hulu、美团、广发证券、去哪儿网、百度的多位国内外知名前端开发专家、资深架构师,主题涵盖响应式布局、Redux、Mobx、状态管理、构建方案、代码复用、个性化图表定制度等前端开发重难点技术话题。技术解析加项目实战,帮你开拓解决问题的思路,增强技术探索实践能力。全天六场深度技术分享,现在仅需169元,限时优惠中,详情点击!
